Reverse engineering game archive of London Racer: World Challenge
"London Racer: World Challenge" is fun old racing game. I like it because of nostalgia (I last played it around 2005). And among other places you could also race in Berlin. Game mechanics reminds me of Super Tux Cart.
Wikipedia says that "Davilex closed the game division in 2005 because it was not profitable enough, and their games were generally not well received". But it also says that Germans even made a movie based on a game Autobahnraser, so I would say that's a great success.
But unfortunately the game does not run on my computer, even with Wine. It would be interesting to extract model of some Berlin streets from there. Or car models. Maybe I'll even manage to put them into Super Tux Cart, will see.
You could download it from here.
Apart from WR.exe, archive with game contains files with game data: WR.idx and WR.img
First one contains list of file names, and second one - their contents. Offsets are stored somewhere in idx, but format of idx file is not clear. .img file looks like just concatenated files of the game.
Extracting from .img file
Every .nif file seems to start with the string "NetImmerse File Format, Version 4.2.1.0". We could use that to split them:
with open('WR.img', 'rb') as f:
data = f.read()
chunks = data.split(b'NetImmerse')
chunks = [b'NetImmerse' + c for c in chunks if c.startswith(b' File Format')]
with open('some.nif', 'wb') as f:
f.write(chunks[0])
Installing Blender and NifTools Addon
NetImmerse was popular game engine, used for such games as Morrowind, Fallout and many others. And there is huge community of modders that created tools to work with .nif files.
Here is the instruction to install .nif addon for Blender
After doing what instruction says, some.nif will open, and show a model of wrench:
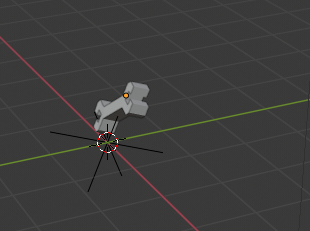
That is repairsmall.nif I would guess. In the game you hit that wrench to repair damage done to your car by other objects that you hit.
Decoding .idx
Some other chunks would not open with the Blender addon, and It would be interesting to know which are which, so let's try to figure out the structure of .idx
Looking for offsets
Offset of first .nif file was 0xFA4. Looking for byte with value A4 gives one at some distance after string repairsmall.nif. After it there is a byte 07. That means little-endian format.
While I was trying to calculate distances from filename field to offset field, I found the page that describes format for another version of racing game from the same developer - London Racer: Police Madness
It gives some important tips. Image file is indeed just concatenated files, but index is a little bit more complex. It contains also directories. That is the correct suggestion from that page. Another correct suggestion was that size of file is stored in index twice. But unfortunately offsets and sizes of the fields do not match.
I wrote some python snippets to load binary data, and do a search in it. To test hypothesis that file offset should have constant distance from file name.
import struct
import string
import re
def load_file(fn):
with open(fn, 'rb') as f:
return f.read()
# Find all offsets of pattern in data
def all_offsets(pattern, data):
return [m.start() for m in re.finditer(pattern, data)]
img = load_file('WR.img')
idx = load_file('WR.idx')
nif_offsets = all_offsets(b'NetImmerse File Format', img)
# offsets of nif file offsets in idx.file
nif_offset_offsets = [
idx.find(struct.pack('<i', o)) # search for given integer in little-endian format
for o in nif_offsets
]
# offsets of ends of names of niff files - 4 bytes
nif_name_offsets = all_offsets(b'\.nif\x00', idx)
# Distance between the two
[b-a for a, b in zip(nif_name_offsets[:10], nif_offset_offsets[:10])]
[17, 19, 18, 17, 20, 18, 20, 1420, 1428, 1436]Hm, not always the same.
Looking at the hex
I also tried some hex editors. Hexinator is fancy one, where you could comment and mark different bytes with different colors. But it crashed for me, so I uninstalled it. Ghex is simple one, and I don't use hex editors so often, so I kept it. But lack of color was making it hard to look at all that numbers, so I wrote short function to pretty print binary.
nocolor = "\033[0m"
red = "\033[31m"
green = "\033[92m"
visible_charset = bytes(string.digits + string.ascii_letters + string.punctuation + ' ', 'ascii')
def is_visible(b):
return b in visible_charset
def pprint(data, columns=10, column_width=4):
for i, b in enumerate(data):
if i % (column_width * columns) == 0:
print()
if i % column_width == 0:
print(end=' ')
r = '%02X' % b
if is_visible(b):
r = '%s%2s%s' % (green, chr(b), nocolor)
if b == 0:
r = '%s 0%s' % (red, nocolor)
print(r, end='')
print()It prints string values in green, zero bytes in red, and everything else as hexadecimal numbers in white. In groups of 4 bytes:

Grouping by 4 bytes helps the most. From there you see that after the name of the file there are two repeating groups of 4 bytes. For example after wr.ini - 840F 0 0 and again 840F 0 0. After repairsmall.nif - A7 8 0 0. I checked - size of file with that wrench is 14503 bytes, which is 0x38A7 in hex or A7 38 00 00 in little-endian format. That 8 is green, which means ASCII, and ASCII code of character '8' is 56 or 38 in hex.
Filenames end with byte 0 , like proper C strings, but if position of next byte is not divisible by 4, more zero bytes are added for padding. That explains small variations in distances between filenames and offsets of offsets.
After that two fields, goes another unknown 32-bit field, and then 32-bit offset of file. Then another unknown 4 bytes, and then 8 zero bytes. Or we could look at that from the other point of view, and say that each filename record starts from 8 zero bytes. Directory names also seems to be prefixed by 8 zero bytes. Apart from that, they seem to contain 8 bytes of data. Some of that bytes probably should be number of directories.
Since first string in index after the header seems to be file, some values preceding it are probably data for the root directory. Maybe 2 is number of objects in the root directory? wr.ini and data? Otherwise it's 01 008 0, which corresponds to 524289 and seems too much.
Trying to unpack
To summarize file structure:
- Header: 48 bytes
- int32 - number of items in root folder
- Then items
Each item:
- 1 byte - 1 = file, 0 - folder
- 3 unknown bytes
- 8 zeroes
- Name, null-terminated string, padded with zero bytes to have total length a multiple of 4
- Fields, depending on type
Fields for file:
- int32 - size
- int32 - size again, same value
- int32 - unknown
- int32 - offset
Fields for folder:
- int32 - number of items
Here is code to read structure like this:
class IdxReader():
def __init__(self, filename):
self.file = open(filename, 'rb')
self.file.seek(48) # skip header
def read_int(self):
data = self.file.read(4)
decoded = struct.unpack('<l', data) # unpack it as little-endian int
return decoded[0]
def read_string(self):
res = []
while True:
c = self.file.read(1)[0]
if c == 0:
pad = self.file.tell() % 4
if pad > 0:
self.file.read(4 - pad)
return ''.join(res)
res.append(chr(c))
return res
def read_item(self):
is_file = self.file.read(1)[0] # type of item
self.file.read(3) # unknown bytes
self.file.read(8) # zeroes
name = self.read_string()
print(name)
if is_file == 1:
size, offset = self.read_file_fields()
print('\tfile', size, offset)
else:
self.read_folder()
def read_folder(self):
n = self.read_int()
print('\tfolder', n)
res = []
for i in range(n):
entry = self.read_item()
res.append(entry)
return res
def read_file_fields(self):
data = self.file.read(16)
size1, size2, offset = struct.unpack('<llxxxxl', data)
assert size1 == size2
return size1, offset
def __enter__(self):
return ('root', self.read_folder())
def __exit__(self, type, value, traceback):
self.file.close()It fails, because data for file b_lights.nif have additional 4 bytes. I suspect this is because before that, unknown field between size and offset had value 1, and for this file it is 2. Probably that means additional fields.
After fixing that, by replacing method read_file_fields with
data = self.file.read(16)
size1, size2, pad, offset = struct.unpack('<llll', data)
self.file.read((pad - 1) * 4) # skip some unknown values
return size1, offset.idx file seems to be read without problems.
Unpacking archive
I put the final code of unpacker in this gist, to not overload the post with code.
Only the models from data/nif folder are loading in Blender, models from tracks and vehicle folder crash it, or give error like this:
Executing - Niftools : Blender Niftools Addon v0.0.13(running on Blender 2.82 (sub 7), PyFFI 2.2.4.dev3)
Importing /home/tbunyk/projects/lrwc/unpacked/data/vehicle/b_cop01.nif
NIF file version: 4020100
Reading file
Game set to 'DARK_AGE_OF_CAMELOT', but multiple games qualified
Importing data
Scale Correction set to 0.10000000149011612
Skipped unsupported root block type '<struct 'NiPixelData'>' (corrupted nif?).
Finished
Probably I need to debug Blender Niftools Addon, or maybe check if there is open ticket about this, but that would be another story.
See also
- THE DEFINITIVE GUIDE TO EXPLORING FILE FORMATS - provided a lot of helpful advice. For example it said that strings could be padded, so values align, which nudged me display bytes in groups of 4.